📑 每日商务英语学习推送机器人 – 第一辑
项目目标
在已有牛马工作提醒机器人、热搜王机器人的加持下,上班已经变得很有趣了。但我们作为专业的职场人,不能停下学习的脚步,因此商务英语学习机器人项目应运而生。
- 学习模块:每天推送 5 个商务英语单词/短语(附中文解释与英文例句)。
- 复习模块:随机抽取 10 个已学习的词汇进行复习,形式为互动题,如“给中文提示,用户答英文单词”。
方案对比
方案一:AI 动态生成
- 实现方式:调用 AI 接口实时生成单词、中文解释与例句;同时使用 SQL 数据库存储已学词汇,用于去重和复习。
- 优点:内容灵活、可无限扩展,无需提前准备完整词库。
- 缺点:依赖 AI 平台,存在接口费用和服务器性能开销;生成内容一致性和质量可能不稳定。
- 适用场景:适合需要动态、个性化内容,但需承担额外成本与服务器压力。
方案二:固定词库驱动 ✅(我使用的)
- 实现方式:
- 预先将商务英语词汇存入 SQL 数据库,包括中文解释和例句。
- 数据表增加状态字段,如是否已学习、是否待复习。
- 机器人每天从数据库抽取词条进行推送与复习。
- 优点:
- 稳定性高,不依赖 AI 接口,推送内容可控。
- 成本低,运行开销极小。
- 易扩展,可在此基础上接入 AI 自动生成补充内容。
- 缺点:
- 前期需要收集、清洗词库数据。
- 内容相对固定,扩展性不如动态生成。
- 小结:先期上线及长期稳定运行推荐方案二,后续可结合 AI 进行增强。
数据库设计
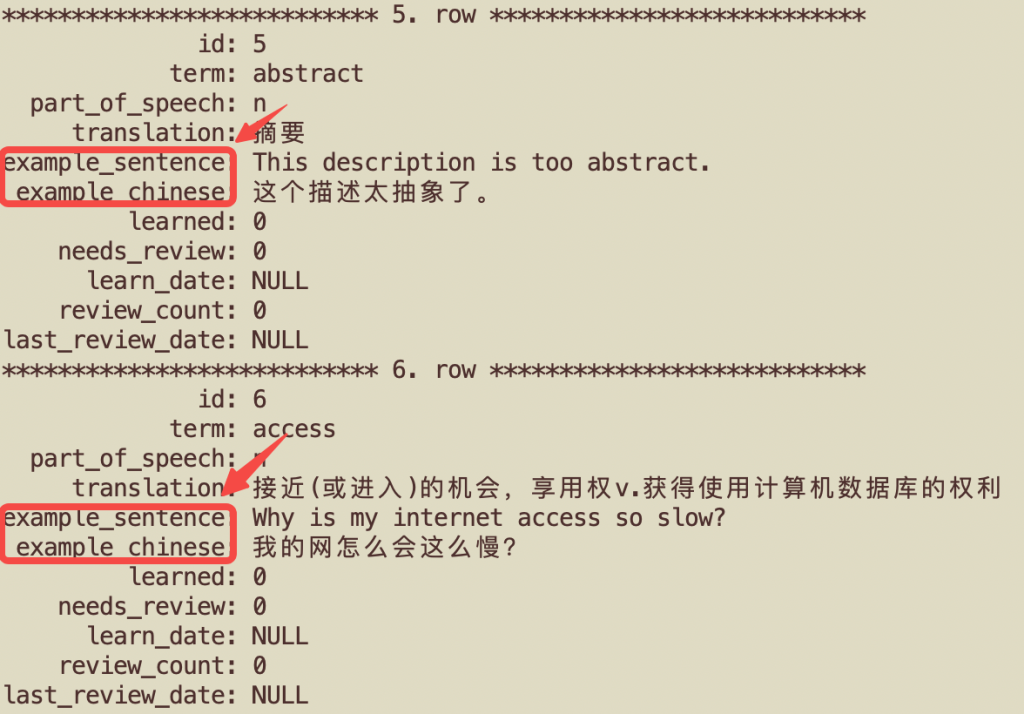
Create Table: CREATE TABLE `business_vocab` ( `id` int NOT NULL AUTO_INCREMENT, `term` varchar(255) NOT NULL COMMENT '英文单词或短语', `part_of_speech` varchar(50) DEFAULT NULL COMMENT '词性(如n.、v.、adj.)', `translation` text NOT NULL COMMENT '中文解释', `example_sentence` text NOT NULL COMMENT '英文例句', `example_chinese` text COMMENT '(可选)中文例句翻译', `learned` tinyint(1) DEFAULT '0' COMMENT '是否已学习', `needs_review` tinyint(1) DEFAULT '0' COMMENT '是否标记为待复习', `learn_date` date DEFAULT NULL COMMENT '首次学习日期', `review_count` int DEFAULT '0' COMMENT '复习次数', `last_review_date` date DEFAULT NULL COMMENT '上次复习日期', PRIMARY KEY (`id`), UNIQUE KEY `unique_term` (`term`) ) ENGINE=InnoDB AUTO_INCREMENT=512 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
数据抓取与清洗
1. 数据来源
- BEC 商务英语初级必备 2000 个词汇,按字母 A–Z 分类。
(这里吐槽一下这个网站,实际几个页面抓去下来根本没有2000个词)
2. 清洗步骤
- 去除重复词条
- 保留英文例句,中文缺失时填充“暂无例句”
- 遵守网站 robots.txt 反爬协议
- 格式化为 SQL 可导入格式
3. 例句补全
- 使用开源的 Tatoeba Api https://tatoeba.org/en/api_v0/search?from={from_lang}&query={word}&to={to_lang}
- 核心优化:
- 有英文就保留
- 中文缺失则填充默认值 暂无中文翻译
- 增加日志提示区分完整例句和仅英文例句
- 单请求示例:

4. 批量导入 MySQL
- 优化脚本 v2,实现英文例句保留、中文缺失填充
- 使用 UPDATE 和 SELECT 分批处理未填充例句的词汇
刷库/初始化字段语句:
UPDATE business_vocab
SET learned = 0,
needs_review = 1,
learn_date = NULL,
review_count = 0,
last_review_date = NULL;
核心清洗脚本(v2 亮点)
# 核心功能:
# 1️⃣ 查询未填充例句的词汇
# 2️⃣ 调用 Tatoeba API 获取英文例句和中文翻译
# 3️⃣ 中文缺失时填充默认值
# 4️⃣ 日志区分“完整例句”和“仅英文”
# 5️⃣ 更新到 MySQL
def query_tatoeba_example(word, from_lang="eng", to_lang="cmn"):
...
# 返回格式:
# {"example_sentence": "英文例句", "example_chinese": "中文翻译或默认值"}
日志示例:
✅ 单词[abroad] 成功获取完整例句(英文:Abroad is...) ℹ️ 单词[absenteeism] 获取到英文例句,中文缺失(英文:Absenteeism refers to...) ❌ 单词[nonexistent] 未找到任何英文例句
刷库逻辑:
- 查询 example_sentence = ‘暂无例句’ 的记录
- 调用 API 补全
- 更新 example_sentence 和 example_chinese
- 自动提交事务,异常回滚
V1 脚本结果示例:business_vocab_example_query_v1.py
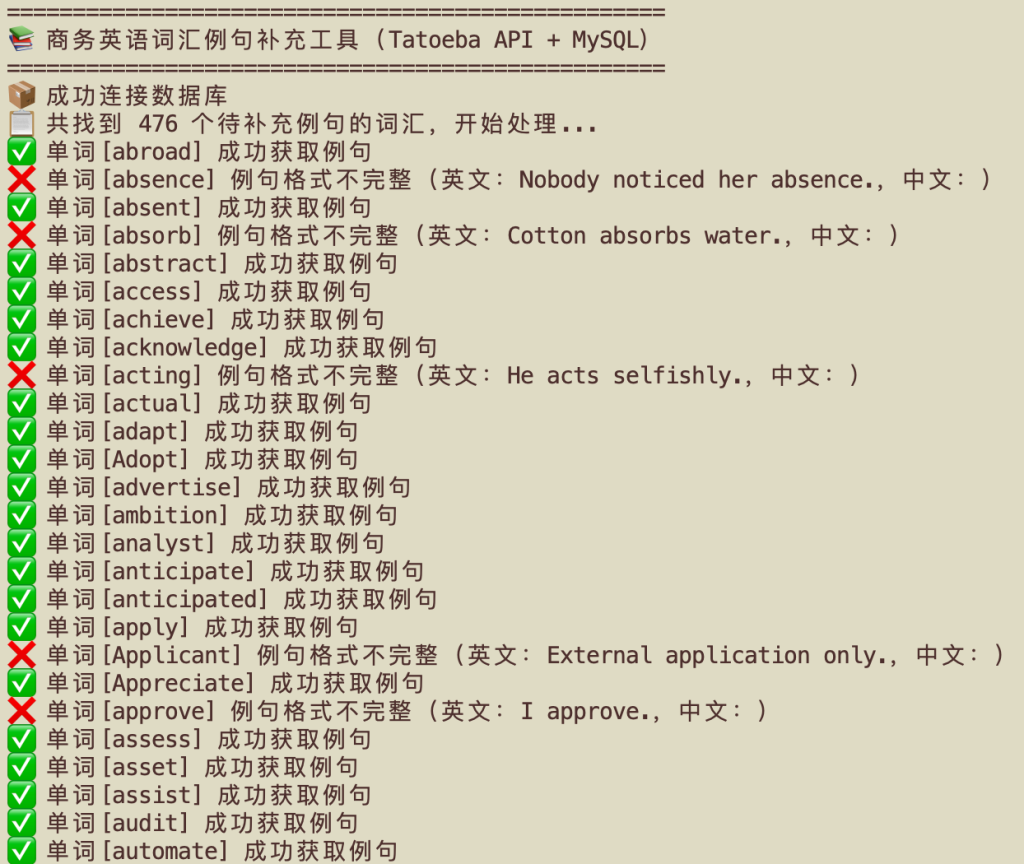
V2 脚本结果示例:business_vocab_example_query_v2.py

SQL 写入中英文例句:
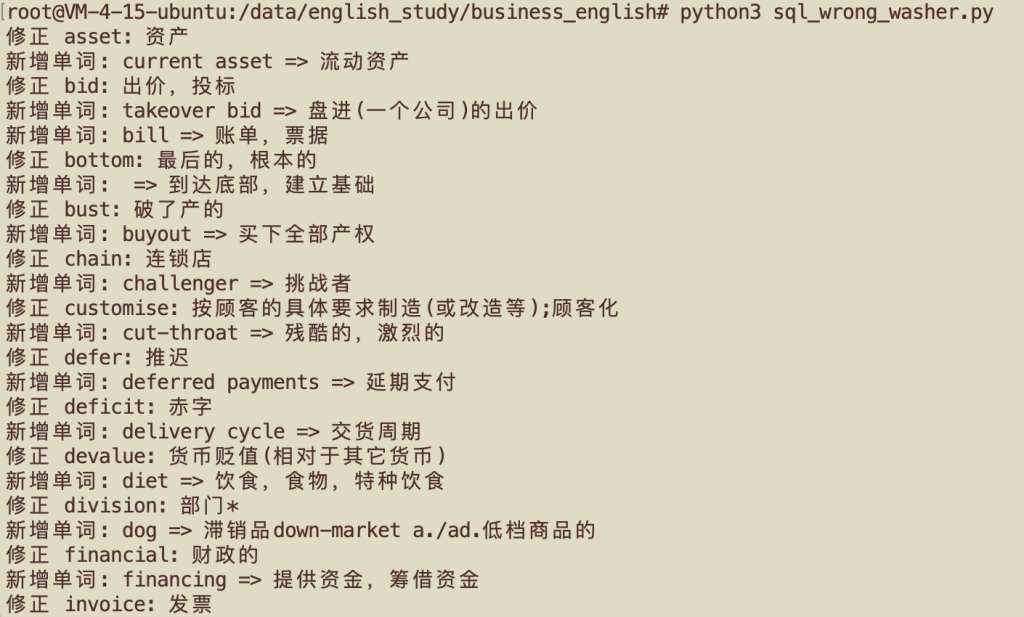
清洗时遇到的问题
部分单词被清洗到了上个单词的translation中

使用 sql_wrong_washer.py 脚本再次清洗、修正
学习与复习逻辑
- 学习推送:每日抽取 5 条 learned = FALSE
- 复习推送:随机抽 10 条 needs_review = TRUE,权重按复习次数调整
- 标记已复习:
UPDATE business_vocab
SET review_count = review_count + 1,
last_review_date = CURDATE()
WHERE id IN (...)
飞书卡片推送
- 动态生成 Markdown 卡片
- 随机决定“中文提示答英文”或“英文提示答中文”
- 包含上次复习时间、例句
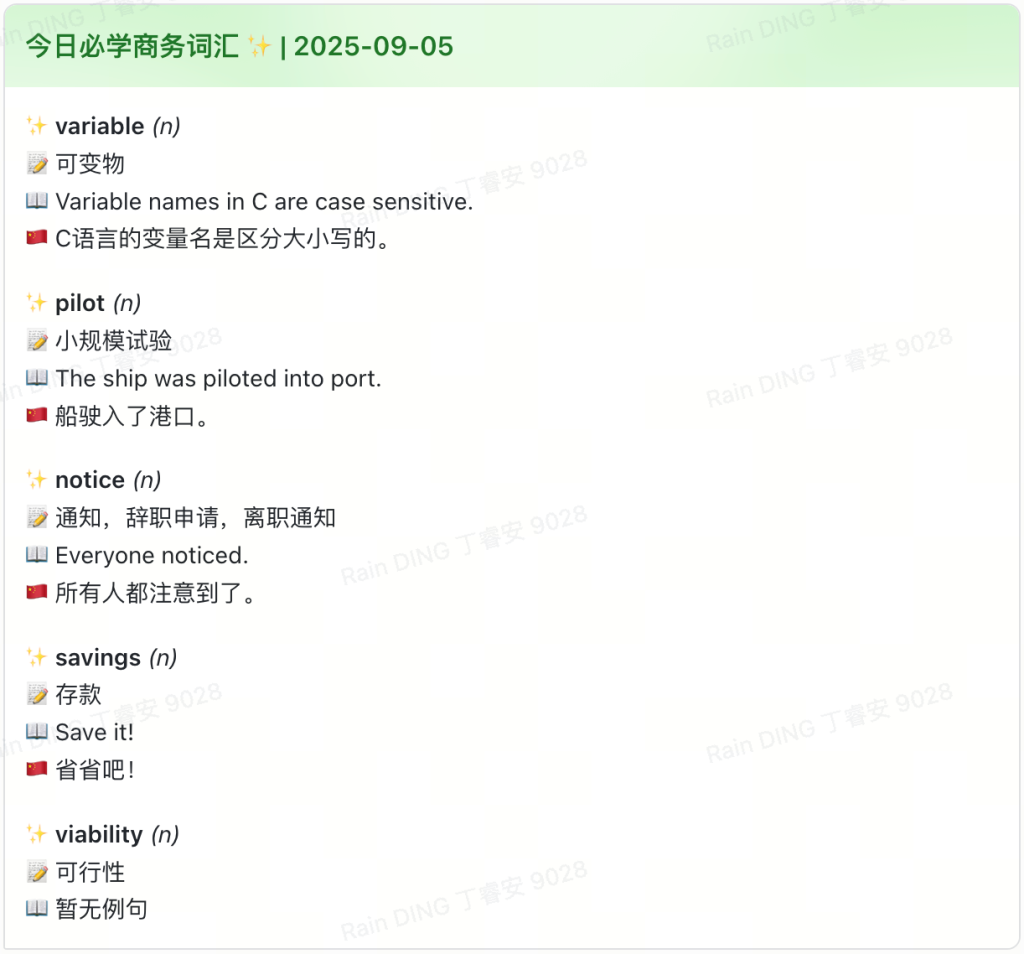

单次推送脚本:
循环版脚本:
可扩展方向
- AI 动态生成例句
- 记忆曲线算法优化复习频率
- 个性化推送,根据用户答题情况调整难度
- 可视化统计:每日学习量、复习量、正确率等
总结
- 清洗与刷库环节是保障推送质量的关键
- v2 脚本优化了日志提示、中文缺失处理和批量更新逻辑
- 固定词库驱动方案保证稳定性,同时为后续 AI 扩展提供基础